AI 的「嗅觉测试」:从结果监督到过程监督,我们如何教机器真正地思考?
就在昨天(2025 年 6 月 14 日),我在收听 Lex Fridman 的播客时,被陶哲轩(Terence Tao)的一个观点击中了。他评价当前的 LLM (大语言模型)时说,AI 已经能通过「视觉测试」(The Eye Test),但在「嗅觉测试」(The Smell Test)上却一败涂地1。
他解释说,AI 生成的数学证明,格式工整、看似无懈可击(视觉测试),但领域专家去「闻」其内在逻辑时,总能发现那些不合直觉的、笨拙怪异的路径。它缺乏专家们沉浸多年才能拥有的、对问题本质的深刻洞察与策略美感——那种隐喻性的数学「气味」。
这番话精准地刺破了当前 AI 繁荣表象下的核心问题:我们所构建的 AI,或许正在成为一个越来越强大的「答案机器」,却始终未能成为一个真正的「思考者」。
在这篇文章中,我想和大家深入探讨这个「嗅觉」的来源,以及它为何成为了当前 AI 发展的关键瓶颈。我们将引入「过程数据」这一概念,解释为何它的稀缺性限制了 AI 的深度推理能力。最后,我们将一同审视学术界与工业界的前沿探索——「过程监督」(Process Supervision),看看它是如何在这片迷雾中,开辟出一条通往真正「思考机器」的道路。
诊断病根:AI 为何缺乏「嗅觉」?
要理解 AI 为何缺乏「嗅觉」,我们必须审视其「食粮」。长期以来,我们喂给 AI 的,绝大多数是所谓的「结果数据」2。
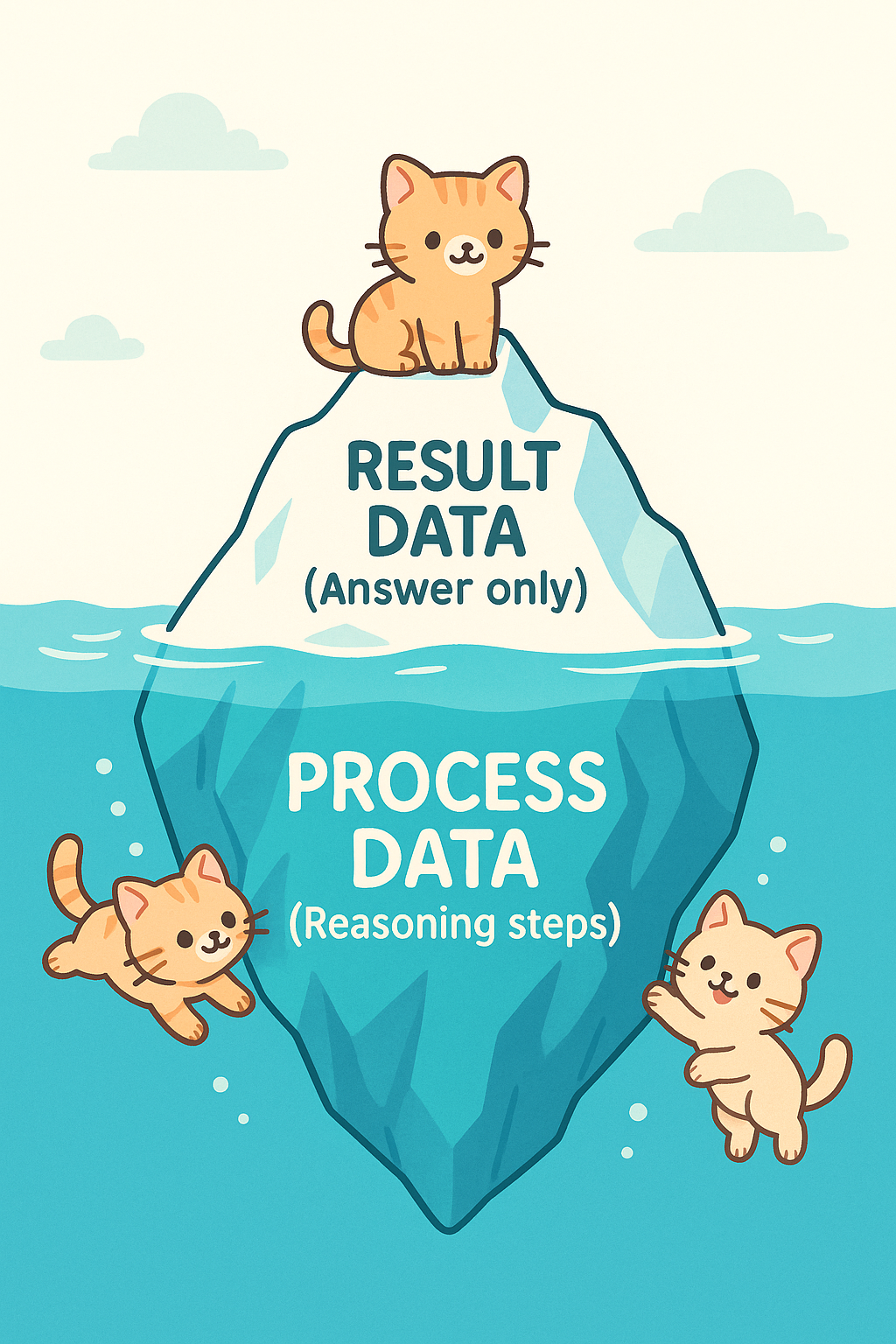
「结果数据」 vs 「过程数据」
「结果数据」很简单,就是「问题-答案」对。
- 问题:「求解方程 」
- 答案:「」
这种方式高效催生了我们今天所见的各类 AI 应用,但它存在一个根本缺陷:只告诉 AI 「是什么」,却没有告诉它「为什么」以及「如何得到」。它只展示了旅途的终点,却隐藏了过程。
与此相对,我们引入一个核心概念——「过程数据」2。它不仅包含最终答案,更包含了达成该答案的、可验证的、一步步的推理链条。
- 问题:「求解方程 」
- 过程数据:
- 目标:求解变量 。
- 第一步:方程两边同时加上 ,得到:。
- 第二步:化简方程,得到:。
- 第三步:方程两边同时除以 ,得到:。
- 最终答案:计算结果为 。
对比之下,前者是孤立的知识点,后者则是一张完整的「思维地图」。
费马大定理背后的「冰山」
为了更深刻地体会这种差异,让我们以安德鲁·怀尔斯证明费马大定理为例。他于 1995 年发表的长达百余页的论文,是一份完美的「结果数据」。但在这背后,是他长达八年与世隔绝的工作,以及海量记录了所有失败路径、策略转变和纠错迭代的草稿笔记。
这些笔记,才是最宝贵的「过程数据」。
一个只学习了最终论文的 AI,学会了欣赏一座宏伟大厦。但一个学习了那些笔记的 AI,才有可能学会如何成为一名真正的建筑师。
这就是 AI 缺乏「嗅觉」的根源。 人类专家的「嗅觉」或「直觉」,正是在长年累月的实践中,内化了海量「过程数据」后形成的高级模式识别能力。他们不仅知道什么是对的,更知道哪些是错的。而我们现在的 AI,训练数据里几乎全是那一百页的「最终论文」,从未体验过那八年的艰辛,自然无法习得这种宝贵的「嗅觉」。
过程数据的「稀缺困境」
高质量的过程数据之所以如此稀缺,主要有三大原因:
- 极高的标注成本:创建过程数据需要领域专家投入大量时间,详细阐述思维过程,审核成本极高。
- 成果发表的惯例:学术界和工业界倾向于发表经过美化的最终成果,而隐藏了宝贵的中间过程和失败尝试。
- 惊人的规模鸿沟:LLM 的训练需要万亿(Trillion)级别的 Token,而公开的过程标注数据集规模通常只有百万(Million)级别3,存在恐怖的数量级差距。
这三大原因,共同导致了「过程数据」的极度稀缺,使其成为限制 AI 从「答案机器」向「思考者」跃迁的关键瓶颈。
瓶颈显现:一个精通形式的「拟态大师」
在「结果数据」的喂养下,AI 成为了一个我们既熟悉又陌生的存在。它能力超凡,却又时常展现出令人费解的脆弱。它精准地掌握了各种文本的「语法」和「形式」,知道数学证明、法律文书和计算机代码应该长什么样。
这就是为什么 AI 能轻松通过「视觉测试」。它生成的文本在形式上无懈可击。然而,形式的完美掩盖了内容的空洞。缺乏「过程」的训练,让 AI 错失了成长为真正智能体的三大关键要素:
错失了真实的推理能力:AI 擅长在见过的数据点之间进行「插值」(Interpolation),但不擅长面对全新问题进行「外推」(Extrapolation)。因为它学习的是解答模板,而非普适的问题分解和解决策略。
错失了可靠性与鲁棒性:只看结果的训练会激励模型寻找「捷径」(Shortcut Learning),导致其基于表面统计关系做出判断。这使得模型非常脆弱,当问题换种方式提问时表现就可能一落千丈,这也是「幻觉」(Hallucination)现象的重要成因。
错失了可解释性与可信赖度:一个只给你最终答案的 AI 是一个彻底的「黑箱」。我们无法追溯其决策逻辑,无法在它犯错时定位问题,更无法在医学、自动驾驶等高风险领域真正地信任它。
幸运的是,在问题的诊断之处,正是解决方案的萌芽之地。一群顶尖的 AI 研究者,已经开启了一场名为「过程监督」(Process Supervision)的探索。
破局之路:「过程监督」的三次浪潮
「过程监督」的核心思想非常直白:与其只奖励最终的正确答案,我们不如对推理过程中的每一个正确步骤都给予奖励。
这就像一位耐心的数学老师,会一步步地教学生换元、化简,并对每个正确步骤给予及时反馈。这场革命,大致可以分为三个波澜壮阔的阶段。
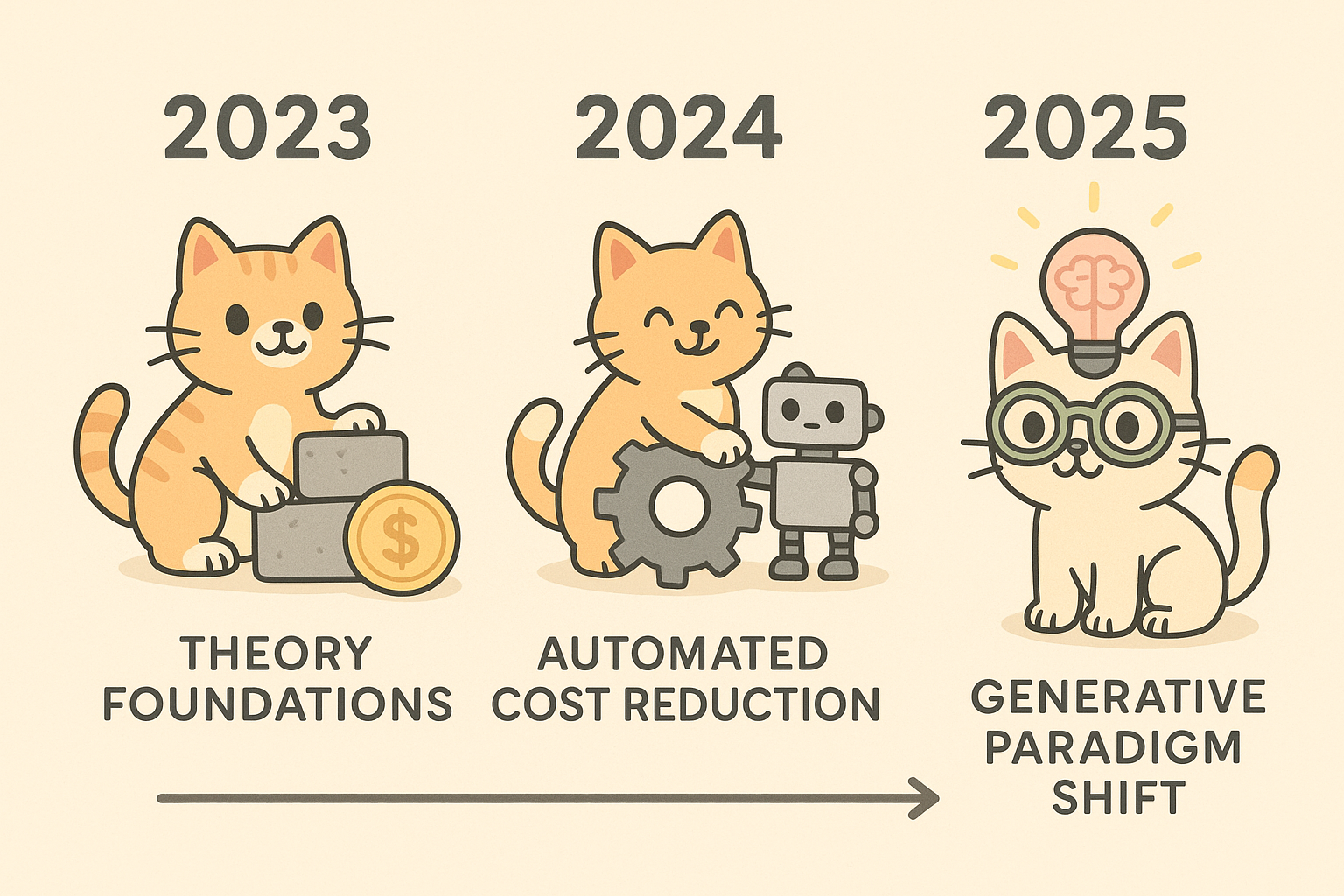
第一阶段:理论奠基与昂贵的「黄金标准」(2023)
序幕由 DeepMind 和 OpenAI 拉开。2022 年末,DeepMind 的论文首次系统性地区分并验证了「过程监督」的优越性。而 OpenAI 2023 年发布的里程碑工作《Let’s Verify Step by Step》,则通过雇佣大量专家对数学解题步骤进行逐一标注,构建了包含约 80 万步过程标签的数据集 PRM800K。
利用该数据集训练的模型,在 MATH 测试集上的正确率从约 72%4 跃升至 约 78%。这一巨大飞跃向业界宣告:过程监督是有效的,但其人力成本也是天文数字,几乎无法被复制和推广。
第二阶段:进击的自动化与成本赛跑(2024)
第一阶段的成功,直接催生了第二阶段的核心议题:如何让这条路变得便宜? 2024 年,研究焦点迅速转向「自动化降本」。
- 像下棋一样做题:Math-Shepherd 等工作创造性地引入蒙特卡洛树搜索(MCTS),让模型像 AlphaGo 一样自对弈、自探索,自动生成数十万步有效的过程数据。
- 精准定位错误:研究者引入「二分搜索」思想,以极高效率自动定位推理链中的第一个错误步骤,大大提升了数据标注效率。
- 更精细的对齐:Step-DPO 等技术借鉴了指令微调思想,让模型从「给步骤打分」变为「判断哪个步骤更好」,实现了更稳定高效的对齐。
与此同时,专门评测模型「定位错误」能力的基准 ProcessBench 诞生。这种「模型开发」与「基准评测」的飞轮效应,推动着该领域走向成熟。
第三阶段:范式转移与生成式智慧(2025)
进入 2025 年,我们见证了最深刻的一次范式转移:我们是否能让 AI 自己来「生产」过程数据? 核心思想从「数据驱动算法」转变为「算法驱动数据」。
实现这一构想的代表作是 ThinkPRM。研究者们仅用了 PRM800K 数据集中不到 1% 的「黄金种子」(约 8000 条5),教会模型如何生成详细、可验证的「思考链」。掌握这项技能后,模型便能对自己生成的其他海量解题步骤进行自我验证和打分。
结果是惊人的:仅用 8000 条人工标签的 ThinkPRM,其表现全面超越了使用 80 万条人工标签的第一代模型。这标志着「过程监督」进入了「生成式」时代,对人工数据的依赖降低了两个数量级。
与此同时,纯自动化路线也走向极致。OmegaPRM 通过一套全自动流水线,成功生成了 150 万步过程标签。研究者们也开始将过程监督的思想拓展到数学和代码之外,如 LongDPO 就将其成功应用于需要创造力的长文本写作领域。
四、地平线上的新挑战
攻克了「过程数据稀缺」的瓶颈,并不意味着我们已抵达终点。旧问题的解决,往往伴随着新问题的浮现。
新瓶颈一:算力与经济学
我们用对「算力」的依赖,替换了对「人力」的依赖。无论是 MCTS 的搜索还是 ThinkPRM 的生成验证,都是计算密集型的「吞金巨兽」。成本瓶颈从「人力」转移到了「算力」,这可能依然是将多数玩家排除在外的门槛。
新瓶颈二:可解释性的回归
我们引入过程监督的初衷之一是打开 AI 的「黑箱」。但当自动化达到极致,AI 自我生成的推理路径可能再次变得「非人」,充满了人类难以理解的捷径。我们可能最终会面对一个更强大,但也更难以捉摸的新「黑箱」。我们追求的是高效的「异类智能」,还是可共鸣的「伙伴智能」?
新瓶颈三:评测与安全的滞后
目前,过程监督的成功主要集中在数学、代码等拥有客观评判标准的领域。但在法律、科研、商业决策等更模糊、开放的领域,我们极度缺乏标准化的评测基准。此外,如何在利用过程监督优势的同时,保护商业研发中的核心机密,也是其产业化落地前必须解决的关键难题。
结论:从喂养数据到构建生态
行文至此,让我们回到陶哲轩的「嗅觉测试」。
回顾过去数年的征途,我们可以欣慰地说,AI 界已经找到了通往习得「嗅觉」的正确道路——「过程监督」。我们见证了它从昂贵的理论验证,到高效的自动化流水线,再到颠覆性的「生成式」自我演进。
这趟旅程最深刻的启示是:未来人工智能的发展,其核心将不再是「喂养」AI,而是「赋能」AI。
我们的角色,正在从一个为模型准备天量食粮的「饲养员」,转变为一个「生态构建师」。我们的任务,是设计出更精巧的初始规则与环境,让 AI 在这个生态中自我探索、自我纠错、自我成长,最终自己「生产」出我们所需的智慧。
我们正处在一个新时代的黎明。一个 AI 不再仅仅是我们的高效工具,而是有可能成为我们真正的「思考伙伴」(Thinking Partner)的时代。这条路依然漫长,但现在,我们至少已经能闻到那来自未来的、令人兴奋的「气味」了。
Footnotes
这是我的文学化表述,陶哲轩的原话是:「So the sense of smell, this is one thing that humans have, and there’s a metaphorical mathematical smell that it’s not clear how to get the AI to duplicate that eventually. So the way AlphaZero and so forth make progress on Go and chess and so forth, is in some sense they have developed a sense of smell for Go and chess positions, that this position is good for white, it’s good for black. They can’t initiate why, but just having that sense of smell lets them strategize. So if AIs gain that ability to a sense of viability of certain proof strategies, because I’m going to try to break up this problem into two small subtasks and they can say, “Oh, this looks good. The two tasks look like they’re simpler tasks than your main task and they’ve still got a good chance of being true. So this is good to try.” Or “No, you’ve made the problem worse, because each of the two subproblems is actually harder than your original problem,” which is actually what normally happens if you try a random thing to try normally it’s very easy to transform a problem into an even harder problem. Very rarely do you transform into a simpler problem. So if they can pick up a sense of smell, then they could maybe start competing with a human level of mathematicians.」 ↩︎
Google 在 Gemma 论文中写明 「We trained Gemma models on up to 6 T tokens of text」,表明主流 LLM 的预训练语料已达万亿量级。而 OpenAI 公布的 PRM800K 数据集只含 80 万 步骤级标签,规模不足一百万。 ↩︎
在 MATH 数据集代表性子集的 best-of-1860 搜索下解决率从 72.4%提升至 78.2%。 ↩︎
原文称仅用 ≈ 1 % PRM800K 进行人工标注;PRM800K 含 800 000 步标签,故约为 8000 条。 ↩︎